In our journey through the critical role of data in drug development, we’ve uncovered what makes high-quality clinical development data “good”: the indispensable need for expert biomedical data curation to achieve AI-ready data and the significant costs of relying on poor-quality data.
Now, in this final installment, we pull back the curtain on how Intelligencia AI operationalizes these principles. It transforms raw information into a trustworthy foundation for AI-driven decision-making, enabling drug and business development teams to make informed, objective decisions more quickly.
The Intelligencia AI Data Foundation: AI-Ready Clinical Data
For algorithms to excel, any data isn’t good enough. You need high-quality, well-structured, expertly curated, and deeply contextual data. At Intelligencia AI, the six core attributes of good data—completeness, granularity, traceability, timeliness, consistency, and contextual richness—are the pillars on which our industry-leading data platform is built.
- Completeness: Harmonize relevant data from trials, programs, comparators, outcomes, and regulatory context.
- Granularity: Preserve detail at the level where decisions are made (cohorts, endpoints, doses, lines of therapy).
- Traceability: Maintain a clear line of sight back to sources and versions.
- Timeliness: Utilize existing knowledge and update promptly as the world and the data accessible evolve.
- Consistency: Align naming and structures so analyses are comparable.
- Contextual Richness: Pair the numbers with the scientific and regulatory frame that gives them meaning.
Because clinical data often arrives fragmented and conflicting across sources, we have built a robust, repeatable process to add the right data on time and minimize bias.
Our process begins with fact-checking and harmonization, ensuring that each data point is accurate, consistently identified, and usable for machine learning. We catalog sources for every trial and timestamp each field, which is critical for training unbiased models that use only what was known at that point in time. Our databases are refreshed weekly; newly captured data points are available the day after collection.
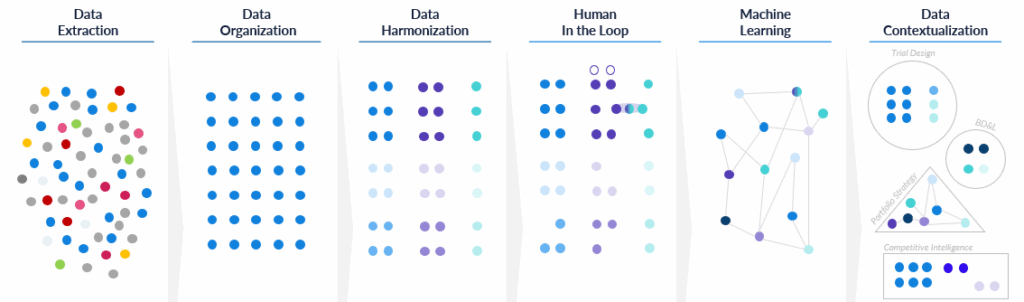
Time-stamping matters more than it might seem. Without it, models can accidentally “peek” at future information, subtly inflating performance and luring teams into false confidence. With strict dating and source tracking, we can reconstruct what a team would actually have seen at the moment of decision and evaluate choices against that reality.
Why Ontologies—and People—Matter for AI-Ready Clinical Data
Biomedicine is full of synonyms and evolving terms. Public databases, while essential, were primarily designed for transparency rather than interoperability. They can suffer from heterogeneity, missing or outdated information, ambiguity, and noise. Ontologies, i.e., shared vocabularies and relationships, enable a platform to interpret “the same thing said in different ways.”
At Intelligencia AI, we realized early on that achieving both goals — creating a complete, granular, rich, and timely database that is also highly curated — required a two-pronged approach, combining automated processes with human expert oversight. To get to AI-ready clinical data at scale, we combine automation with expert review. We utilize natural-language processing to handle high volumes and perform tedious and repetitive tasks, such as identifying entities, extracting structure, and matching close variants. Then, PhD-level experts provide interpretation, validation and context.
A few common patterns where having an expert in the loop is a must-have:
New or ambiguous drug names. The system flags a suspected new entity; experts determine whether it’s truly new, a synonym of an existing asset, a reformulation, or part of a combination that needs separate tracking.
Example: even a small typo can turn hydroxyzine into something that looks a lot like hydralazine. Both are real drugs with very different indications (antihistamine vs antihypertensive). An expert review is needed to prevent these look-alike/sound-alike errors from slipping into models.
Endpoint labeling. Automation captures known terms, but novel or uniquely worded endpoints often need human interpretation to ensure they are mapped to the right concept.
Example: ClinicalTrials.gov might list an outcome measure as “Time to confirmed radiographic progression per modified RECIST v1.1.” A model might automatically map this to progression-free survival, since both involve tumor progression, but the trial actually measures time to progression – a narrower endpoint that excludes deaths before progression. Human review is needed to ensure the measure is classified correctly.
Population definitions. Minor wording changes can shift inclusion/exclusion criteria in ways that matter for comparability. Human review keeps those distinctions accurate.
Example: One trial might enroll “patients with relapsed multiple myeloma after at least one prior line of therapy,” while another specifies “after one to three prior lines of therapy.”
While they sound similar, the second excludes patients who are heavily pre-treated (four or more prior treatments) and often respond differently. Automation might treat these criteria as equivalent, yet human review recognizes that the underlying populations differ in ways that affect cross-trial comparability.
Automation accelerates; expert curation gives the data its decision-grade quality.
From Linked Data Points to Full Program Stories
Beyond cleaning and labeling, we unify information from many sources so programs read as coherent stories. Trials are linked into a chain that reflects a drug’s journey across phases, indications and lines of therapy. Outcomes indicate the comparators against which they were measured. Records are enriched with regulatory context, for example, orphan designations or fast-track status, which may not be available in a single source.
This augmentation does not create new data; it enhances existing data, making it more complete, connected, and useful. A decision-maker can trace the origin of a metric, identify what changed and when, and compare across programs using a stable framework.
Avoiding the High Price of Low-Quality Data
The negative consequences of relying on poor data can be staggering. At Intelligencia AI, we have seen numerous examples of avoidable consequences when pharma teams rely on incomplete or stale inputs.
- Outdated standards of care in phase III. Comparing against a placebo after a competitor has already established a stronger benchmark can doom an otherwise promising program. Even small shifts in the standards of care can alter effect sizes, enrollment feasibility, and regulatory expectations. Timely, AI-ready clinical data helps teams detect these shifts early and recalibrate trial design.
- Overestimating the likelihood of success. This is often rooted in human psychology; after years of effort, people want a program to win. It’s easy to discount signals that point to trouble. We define Probability of Technical and Regulatory Success (PTRS) using consistent inputs and a clear methodology, ensuring that optimism doesn’t influence the numbers. An objective, dispassionate assessment grounded in good data provides a much-needed reality check.
- Overlooking adjacent competition. You might build a strong second-line therapy only to see a new first-line drug shrink your market. Looking narrowly at “direct competitors” can miss a coming sea change upstream. A broader competitive lens, grounded in current trial and label data, reduces that risk and informs go/no-go decisions and commercial planning.
- Overpaying in BD&L. Poor inputs skew Net Present Value (NPV) calculations, as incorrect comparators, outdated response rates, or misinterpreted safety signals can feed into revenue ramps and discount rates. Auctions and urgency only magnify the effect. Using AI-ready clinical data doesn’t remove uncertainty, but it sharpens assumptions so buyers and sellers are at least arguing over the same, current facts.
- Biased and inflated seller and buyer optimism. Sellers naturally emphasize higher PTRS; buyers can also be influenced by bias. Teams are incentivized to “get a deal done,” pipelines need to be filled, and short-term growth targets can push prices upward. Objective, traceable inputs act as a backstop. If the numbers are stretched, the data will show where and by how much.
Across these scenarios, consistent PTRS assessments—grounded in curated, current inputs—support more confident and financially sound strategies in both R&D and BD&L. They also make conversations across clinical, commercial, and finance teams simpler: everyone can see the same facts, traced to the same sources, at the same point in time.
What Changes When You Work With Intelligencia AI
When soliciting feedback from our pharma customers, the differences and value show up in a few practical ways:
- Every field is sourced and dated. You can audit the origin to understand what changes were made and when.
- Weekly refresh cycles keep evidence current; new data points flow into analyses the next day.
- Ontology-driven harmonization means programs are comparable across indications, endpoints, and lines of therapy.
- PTRS, benchmarks, and competitive views are produced from the same underlying, AI-ready clinical data.
These may sound like operational details, but in high-stakes decisions, they can be the difference between ultimate success or failure.
Success Stories Echo the Impact of Good Data
At Intelligencia AI, we help our customers experience the importance of good, expertly curated data every day. The following examples show how our partners and customers use our products and services to inform critical decisions, knowing they can rely on the quality of our data and analyses:
- This case study describes how a biotech company used Intelligencia AI’s models and curated data to identify promising antibody assets for acquisition. By relying on harmonized, high-quality trial and company data, thousands of possibilities were quickly narrowed down to a handful of viable targets. The outcome underscored that credible, decision-grade data made the analysis both fast and defensible.
- This article illustrates real-world cases where AI models, grounded in curated clinical and business data, helped pharmaceutical and biotech investors outperform benchmarks and avoid bad bets. One example demonstrated how the internal assessment of a potential acquisition target overestimated the drug’s PTRS by 45%, whereas the AI model, based on harmonized data, calculated it at just 8%. This triggered the company to walk away from the deal and avoid costly failure.
- In this case study, we describe how Intelligencia AI’s partner ZS leveraged our deep data to optimize tumor selection for a customer. The biopharma company needed to identify the most promising tumor targets for a novel, early-stage antibody-drug conjugate. The complex task required them to assess 16 tumor types and 60 segments—a process that typically takes four to six months—in just two months. With traditional methods, the team could not efficiently aggregate the vast clinical and commercial data for timely decision-making. However, by using Intelligencia AI’s clinical and competitive intelligence data along with other data sources, the task could be completed successfully.
Conclusion: The Foundation for AI in Drug Development All Starts With Data
High-quality clinical development data is not merely a technical detail; it is the prerequisite for building AI models that are accurate and interpretable. In an industry where a wrong decision can cost years and millions, delaying therapies to patients in need, investing in AI-ready clinical data is not optional.
Intelligencia AI’s commitment to meticulously curated, harmonized, and comprehensive data, combined with our advanced AI and human expertise, transforms the chaos of raw public data into decision-grade insights. This empowers pharmaceutical companies to make more confident decisions, accelerate regulatory submissions, and ultimately, bring life-changing drugs to patients more efficiently.
Contact us to discover how you can utilize our industry-leading data platform for your drug development efforts and power your AI with reliable inputs for confident decision-making.




